论文链接:aclanthology
Abstract
大多数中文拼写错误都属于语音错误或者是视觉错误。之前的方法很少运用到这两方面的知识,亦或是严重依赖外部资源来对相似度建模。作者提供了一个端到端的训练模型,利用多模态的信息来提高模型性能。作者从音频和视觉两个方面获得了汉字的拼音和象形文字表示,并且通过自适应门机制将他们结合在一起。最终试验效果很好。
Introduction
中文拼写错误由人的书写错误、语音识别错误、图像识别错误产生。中文拼写纠错作为其他下游任务(比如搜索引擎的信息检索)的最初一步。
中文是一种表意文字,汉字中间没有分隔符号,这使得拼写纠错比英文难。此外,几乎所有中文拼写的错误都是字典里有的汉字,不像英文的错误拼写导致错误单词的产生。
根据研究显示,76%的中文拼写错误属于语音相似错误,46%属于字形相近错误。过去的方法要么就是不能放到端到端模型里进行训练,要么就是依赖于有限的confusion set,只能利用有限的信息。
作者用在text-to-speech任务的Tecotron2和在CV任务中的VGG19, 分别用来提取语音和字形特征。作者把他们和语义表示结合,利用一个自适应门,组成一个端到端的模型。
Related Work
- Rule based method
- automatically acquiring linguistic knowledge from a small set of easily understood rules
- arrange a new grammar system of rules to solve both Chinese grammar errors and spelling errors
- based on an extended HMM, ranker based models and a rule based model
- Statistical based method
- Noisy Channel Model
- utilizing a predefined confusion set
- Deep learning based method
- seq2seq
- BERT as a denosing autoencoder
- GCN
- Soft-maksed BERT
- TreeLSTM
Approach
Problem Formulation
根据中文句子$X$输出修改后的响应句子$Y$,不同于seq2seq任务,输入和输出句子长度相同,并且只需要改几个单词。
Model
3个特征提取模块+1个自适应门模块
特征提取模块提取拼音特征、字形特征和语义特征
最终把每个汉字的整合表示放进一个全连接层,来计算整体词汇的概率,用最高概率的汉字来替换他。
Pinyin Feature Module
使用TTS的模型Tacotron2来对语音表示进行建模。用一个encoder将序列表示成一个embedding layer,用decoder来处理hidden representation,一次一帧的预测梅尔频谱。用teacher forcing的方式训练Tacotron2,数据集为中国女性声音数据集。给定句子$X$,首先将它转换成拼音序列,然后通过查表得到拼音序列。
Glyph Feature Extractor
采用VGG19作为主干网络,用从字形图片找到对应标识符的任务进行finetune。去掉最后的classification layer,用最后的max pooling layer作为字形的feature。
Semantic Feature Extractor
采用BERT作为主干网络
Adaptive Gating
相较于以往只是用相加或相连来融合不同feature,作者创新性地引入了自适应门机制。
$AG(F^p,F^s)=\sigma(F^pW^p+b^p)\cdot F^s$
$AG(F^g,F^s)=\sigma(F^gW^g+b^g)\cdot F^s$
其中$W^p,b^p,W^g,b^g$都是需要学习的参数,激活函数用的是ReLU。
最后的Feature计算方法如下:
$$
F^e=\lambda_p\cdot AG(F^p,F^s)+\lambda_g\cdot AG(F^g,F^s)
$$
其中$\lambda_p + \lambda_g = 1$
最后加一个residual connection:
$$
F^{es}=F^e+F^s
$$
Training
为了最终的分类,$F^{es}$被放入一个全连接层,公式如下:
$$
P(Y_p|X)=softmax(F^{es}W^{fc}+b^{fc})
$$
Loss function使用负似然估计:
$$
\mathcal{L}=-\sum^n_{i=1}\log P(\hat y_i=y_i|X)
$$
Inference
选择每个汉字最高概率作为它的纠正。
Experiments
Datasets
SIGHAN13,SIGHAN14,SIGHAN15,以及通过光学识别和语音识别生成的271k的训练样本。
Baseline Methods
- FASPell
- SpellGCN
- HeadFilt
- BERT
Evaluation Metrics
句子级的度量,而不是汉字级的。因为句子中的所有错误都需要改正,所以句子级的纠错更加严格。
Experimental Setup
SIGHAN13的最优$\lambda_p$和$\lambda_g$分别为0.6和0.4
SIGHAN14和15的最优分别是0.8和0.2。
拼音数为1920,拼音特征的维度是512,字形的维度是25088.
Tacotron2:用开源的代码,按初始参数(除了decay step设为15000)训练了130k步。
VGG19:在字形图片上以batch size为32,learning rate为$5e^{-4}$训练了50个epoch。
Main Results
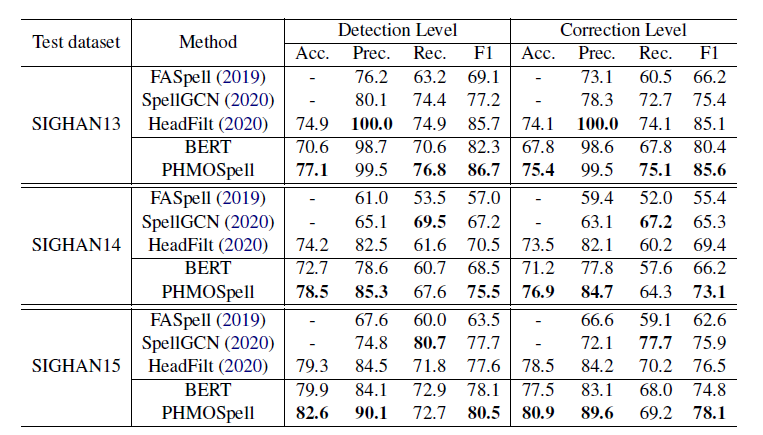
SpellGCN依赖于预先定义好的confusion set,限制了泛化。
HeadFilt只使用了字形知识。
Ablation Study
使$\lambda_p = \lambda_g$,避免偏差。
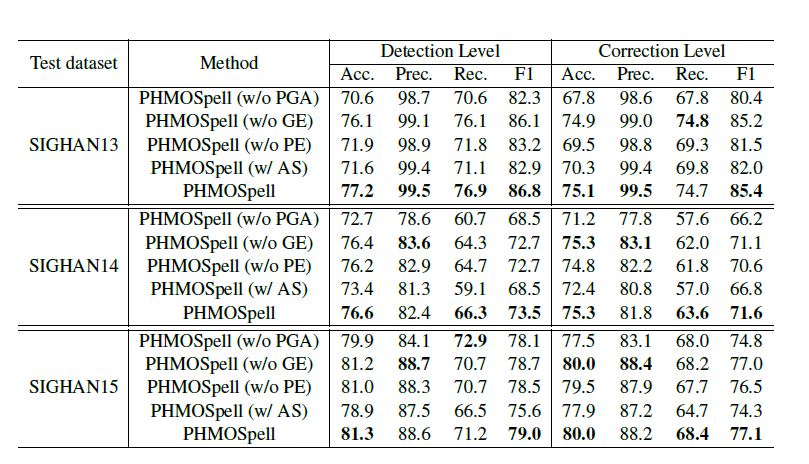
没有adaptive gating strategy导致detection和correction都变差了。
去掉拼音或者字形的特征提取器,去掉拼音特征比去掉字形特征表现降低的更多,说明音调信息对CSC更加关键。两个都去掉结果更加明显,说明拼音和字形对最终表现都有影响。
Effect of Hyper Parameters
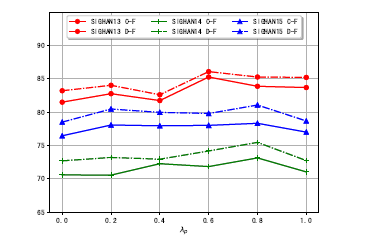
$\lambda$以0.2每次在0到1之间变化。结果显示当$\lambda_p$更大时模型表现更好。
通过之前测试说明的拼音特征对于表现影响较大,因此对不同拼音特征的维度进行了测试:
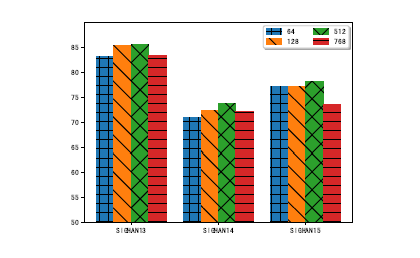
结果表明维度更大表现更好,但是在维度大于512时,结果变差了。原因是bias-variance phenomenon。维度小的特征不能捕捉到所有的拼音关系,导致了更多的偏差;维度大的特征则包含了太多的噪声,导致了更多的方差。这启示我们必须要在维度的选择方面做出权衡。
Features Visualization
为了更直观的理解维度的作用,作者降低了特征的维度,并且用t-SNE进行可视化。
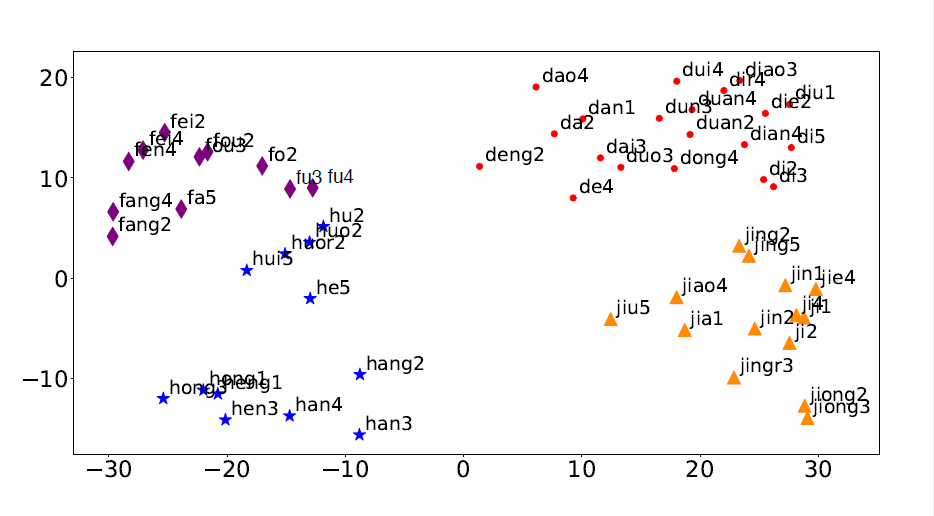
上图展示了开头为d、f、h和j的拼音。可以发现有相似发音的拼音距离更近,说明模型能够很好的把拼音特征和发音特征结合起来。
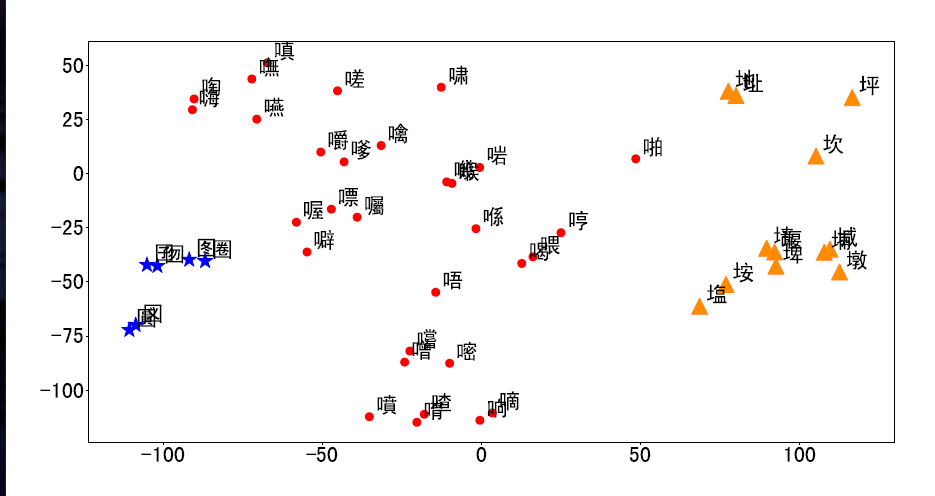
上图展示了偏旁为口和土的字。和拼音一样,也是字形相似的离得越近。