论文链接:aclanthology
Abstract
这篇论文使用pre-training和fine-tuning的方法。相比于以往的mask模型,作者结合了语音特征和同音词,提出了一个新的端到端模型。同时也提出了一种自适应权重的训练识别错误和改正错误的架构。实验效果很好。
Introduction
83%的中文拼写错误结果都是读音相近的词。
- 以往方法
- 当成序列标注的任务,使用CRF或RNN
- GCN的方法
- 用预训练的BERT生成候选词,训练classifier选择最终的改正。
- seq2seq,从confusion set中选取候选词
- 端到端mask BERT模型
- Soft-masked BERT
3和4考虑到了语音知识,其余的都没有考虑到
Methods
模型包含两个部分,检测和改正部分。检测部分把$x_w$ 当成输入,预测出每个汉字的错误率。改正部分把$x_w$和它的拼音序列$x_p$当成输入,预测出修改后的序列$y$。
在经过预训练和微调后,训练出了一个masked language model,叫MLM-phonetics。
Model Architecture
这部分介绍了模型结构,分为Detection Module和Correction Module。
Detection Module
这部分的任务是检测每个汉字是正确与否。用1和0来分别代表错误的和正确的单词。
$$
y_d = softmax(f_{det}(E(e_w)))
$$
其中$e_w$代表的是$x_w$的word embedding,$E$是预训练的encoder,$f_{det}$是全连接层,用于把句子表示映射到二分序列$y_d=(y_{d1},y_{d2},\cdots,y_{dN}),y_{d_i}\in{0,1}$。用$p_{err_i}=p(y_{d_i}=1|x_w;\theta_d)$表示汉字$x_{w_i}$是错的概率。
Correction Module
这部分的任务是根据上一部分的输出生成正确的汉字。这一部分的输入结合了汉字序列和拼音序列。最终生成的序列表示如下:
$$
e_m=(1-p_{err}) \cdot e_w + p_err \cdot e_p
$$
这样平衡了语义特征和语音特征。
Jointly Fine-tuning
模型的目标有2个:
- 训练Detection的参数$f_{det}$
- 调整Detection和Correction的参数,达到最佳的平衡
Loss function:
$$ L_c = -\sum_i p(y_{d_i}|x_w;\theta_d)\cdot\log p(\hat y_i|e_m;\theta_c) $$
$\hat y_{d_i}$是ground-truth detection result,$y_{d_i}$是detection的输出,二者均为0或1。
其中$p(y_{d_i}|x_w;\theta_d)\in (0.5,1]$。它用于平衡两个任务的重要性。当这个概率接近0.5时,说明detection给出了置信度较低的预测,那么主要用于优化$L_d$,当接近1时,说明$e_m$主要由语义或者语音构成,此时就平衡优化$L_d$和$L_c$。最终的Loss function如下:
$$ L_d=-\sum_i \log p(\hat y_{d_i} | x_w;\theta_d) $$
$$\mathcal L = \mathcal L_d + \mathcal L_c$$
Pre-training MLM-phonetics
MLM-base mask了15%的汉字,其中80%是[MASK]标记,10%是随机汉字,10%是自己。
作者在MLM-phoenetics里引入了两种新的替换方法:Confused-Hanzi和Noisy-pinyin。Confused-Hanzi把汉字转成confusion set中的字,训练他们识别打字错误的能力。Noisy-pinyin把汉字变成拼音,训练他们从confusion set中从拼音预测出汉字的能力,这也有助于聚集发音相似的汉字。
MLM-phoenetics是mask了20%的汉字,其中40%是[MASK]标记,30%是Confused-Hanzi,30%是Noisy-pinyin。
Novelty of our method
- 拼音和汉字结合,防止信息丢失,也符合人的直觉。
- 共享encoder,防止input divergence
- 引入了自适应权重,能得到更好的检测结果
Experiments
Benchmark:SIGHAN
数据集分为2部分:第一部分是0.3billion的预训练中文句子语料,第二部分是281K个CSC句子对。第一部分是自己收集的,第二部分是别人论文里的数据集。
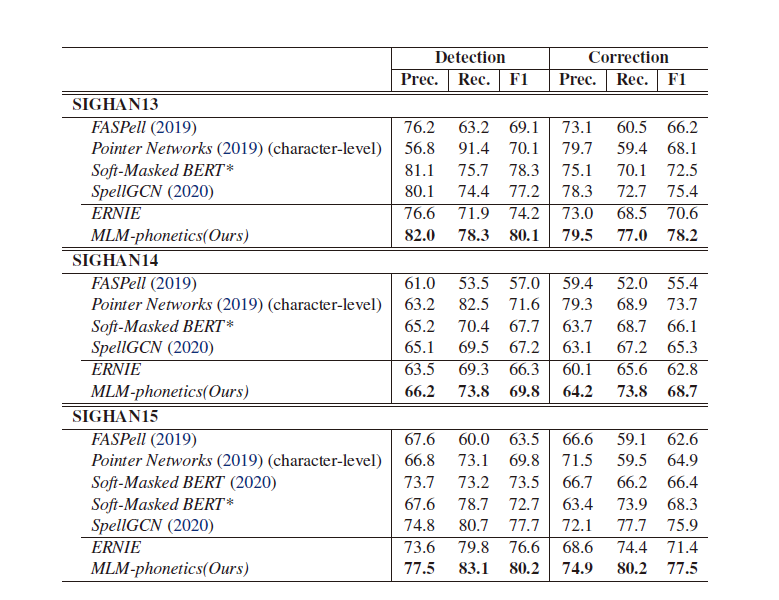
结果如下:
消融实验:
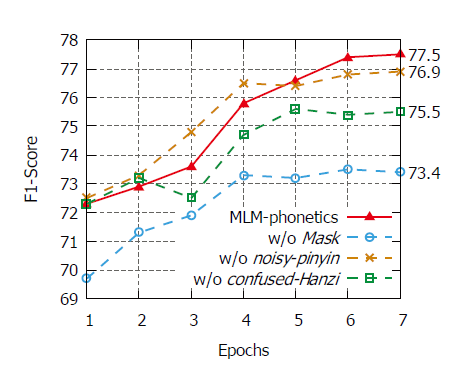
w/o noisy-pinyin:在一开始表现的比较好,推测是因为pinyin embedding和原本的bert输入分布差不多。MLM-phonetics需要通过重构汉字和拼音,所以需要多轮训练,结果也确实如此。
w/o confused-hanzi:受到input divergence的影响。
w/o [mask]:体现出了[mask]对语义理解的重要性。
Error Analysis
Detection Error和Correction Error分别为83.6%和16.4%。
通过分析指导83.6%的Detection Error课分成两种,分别是false negative和false positive,各占41.1%和42.5%。作者解释的原因是“的”“地”“得”无法分辨清楚。